Stanford Hazy Research · 2018–2019
Programmatic Data Labeling for Multi-Sentence Relation Extraction
We extended Snorkel's programmatic labeling framework beyond single sentences, using heuristic labeling functions to generate training data for cross-sentence relation extraction: no manual annotation required. 12% F1 improvement over single-sentence baselines.
UIUC · Stanford University
The Problem
Relations span sentences. Labels don't.
Most relation extraction systems assume both entities appear in the same sentence. In practice, key relations often span multiple sentences, and manually labeling cross-sentence examples is expensive and slow. We needed a way to generate training labels programmatically at scale.
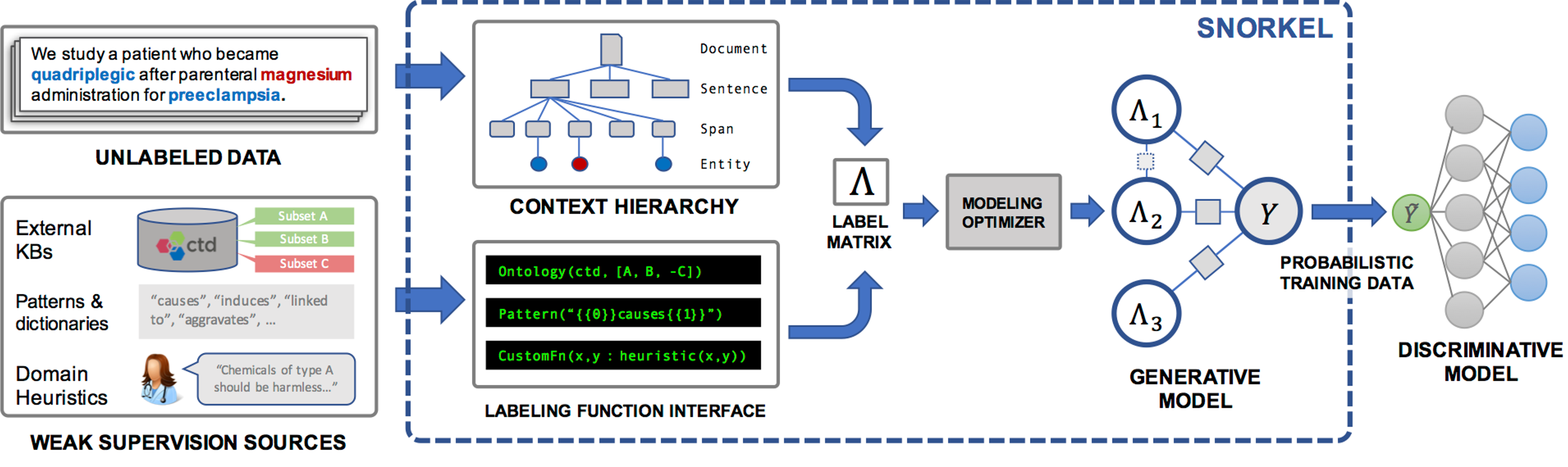
Approach: Programmatic Labeling Functions
Heuristics that write labels, not humans.
Using Snorkel's weak supervision framework, we wrote labeling functions: programmatic heuristics based on dependency paths, sliding windows, and structural signals that automatically label multi-sentence entity pairs. Snorkel's noise-aware generative model combines noisy, overlapping labeling functions into probabilistic training labels.

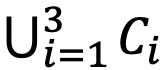

Results
- +12% F1 over single-sentence extraction baselines via novel multi-sentence labeling functions.
- Multi-task learning across sentence spans boosted extraction quality on long-range relations.
- Zero hand-labeled data: all training labels generated programmatically from heuristic functions.
- Collaborated with Alex Ratner (now CEO of Snorkel AI) and Christopher Ré.